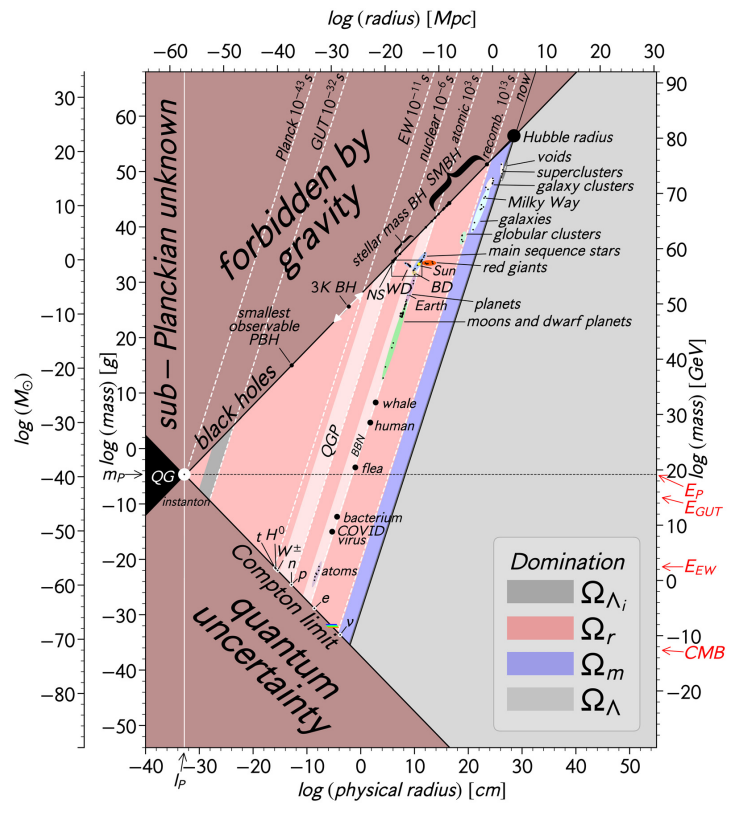
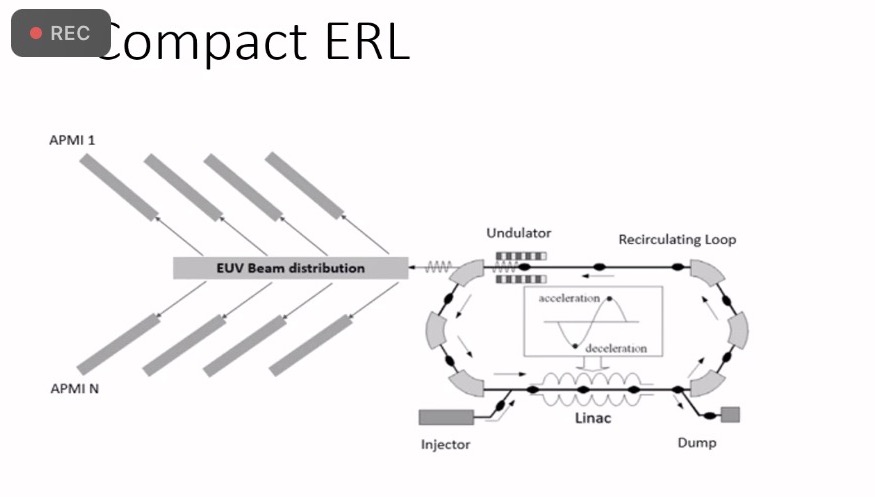
I leave Twitter for a few month, and the science world is all upside down!
The superconductivity community was simmering, with the news that a new compound name LK-99 may be superconducting at room temperature. Eventually, things quenched abruptly, but not without an interesting foray on how science works nowadays, some good takes and a decent media coverage.I first learn about it when I read an article in Ars Technica “What’s going on with the reports of a room-temperature superconductor?” where I saw the name of my friend Sinead popping up. She was in the spotlight because she had run some very complicated simulations to determine whether LK-99 could be a candidate for superconductivity, and found that the material has indeed some interesting features – volume collapse and flat bands – the latter being a common feature of superconductors.Alas, it seems that the results from the initial paper failed to be reproduced by other teams, who in passing found some interesting properties for this class of material. Inna Vishik, who was running the ALS UEC Seminar Series: Science Enabled by ALS-U with me, summarized it well:Now that I have a captive audience…(welcome new followers!) a monster thread on what my paper says, the approximations and the caveats… (1/aleph) https://t.co/twSIsn1Ho9
— Sinéad Griffin (@sineatrix) August 2, 2023
“The detective work that wraps up all of the pieces of the original observation — I think that’s really fantastic,” she says. “And it’s relatively rare.”
LK-99 isn’t a superconductor — how science sleuths solved the mystery – Nature